基于自然语言处理的漏洞检测方法综述笔记
on Paper notes
原文作者:杨伊,李滢,陈恺
信工所、科大网安
计算机研究与发展(Journal of Computer Research and Development)
2021年
Abstract
已有的一些针对漏洞检测的技术:
- 静态检测
- 文档分析法
- 交叉验证法
- 程序分析法
- ……
- 动态检测
2020年来漏洞数量占比最大的5类为:Code Execution, DoS, Overflow, XSS, Gain Information.
基于NLP的检测有大致4部分:官方文档、代码、代码注释、漏洞相关信息,其中除了代码的剩下三种是以文本为基础的(个人感觉这不太靠谱啊)
一个例子:开源软件不遵守使用规范会导致安全问题,如setuid()函数,使用结束以后需要对函数的返回值进行检查(0–Success, -1–Error,同时注意有的时候虽然失败了返回值依然是0)。作者他们研究的是官方文档,提取官方文档中强调的会出问题的点,并以此为依据对应用等进行相应检查(这里应该也是检查文档吧),从而发现问题。比如PulseAudio 0.9.8就没有按照官方文档强调的去做。
而以代码为基础的则是将其作为辅助手段,将代码视为一种特殊的文本,将NLP中的方法加以修改从而进行漏洞检测。
Related Work
静态
Gosain等人分析了主流的静态分析工具,将其分为4类:
- 静态检查 就是看有没有普通的编程错误,包括:可疑赋值、未使用的变量、无法访问的代码(类似于写了某个函数但是从来没调用过)等
- 漏洞发现 发现安全编码引起的缺陷(如缓冲区溢出)、导致程序崩溃的缺陷(如空指针引用)、不正确的程序运行(如未初始化变量就使用)等
- 软件验证 检查程序是否符合规范
- 类型限定符推理 捕获类型限定符之间的关系
基于源代码的静态分析方法:
- 数据流分析 适用的原因:一般情况下程序的漏洞出现的原因恰好是某个特定的变量在特定的程序节点上的性质、状态或者取值不满足程序安全的规定。
- 抽象解释 是一种数学结构的近似理论,特别适用于语义模型的数学结构。其目的是找出程序运行时的语义错误,比如除0或者变量溢出。
- 符号分析
常见的静态分析工具
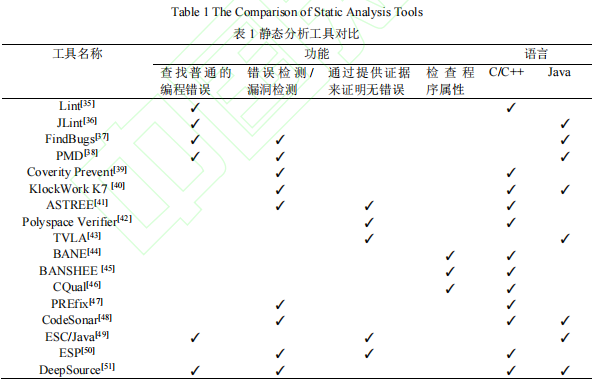
fuzzing
一种半自动化的动态检测方法,本质是向程序中插入异常的、随机的输入来触发不可预见的代码执行路径或者漏洞(个人感觉这个就是一种暴力穷举的方法)。该方法通常根据目的分为两种类型:基于路径覆盖率的模糊测试方法(coverage-based fuzzing),导向型模糊测试方法(directed fuzzing)。
目前主流的路径覆盖率检查工具有:AFL, libFuzzer, honggfuzz, AFLFast, VUzzer, CollAFL等。
导向型fuzzing指的是潜在漏洞位置已知的情况下,寻找可以触发漏洞的PoC(Proof of concept),有针对性的生成一组输入。目前常见的工具有AFLGo, SemFuzz, Hawkeye等。
基于NLP的漏洞检测研究
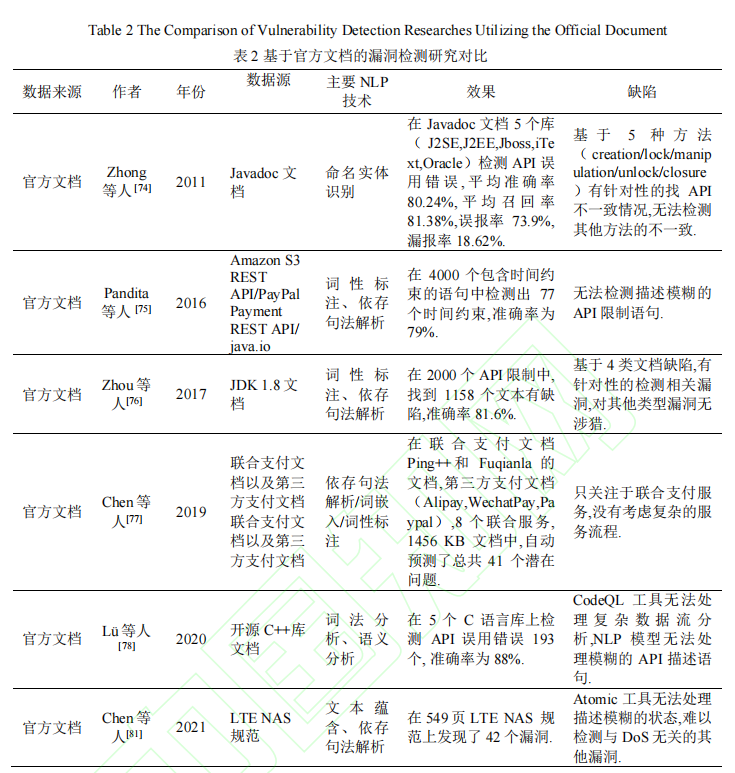
基于官方文档的漏洞检测研究
程序分析的局限性:
- 人工分析推断正确的函数调用规则需要耗费大量专家知识辅助完成,主观性较强,会引入大量的误报
- 代码覆盖范围可能会导致遗漏很多漏洞,产生漏报
这种检测方式的出发点:开发人员需要通过阅读官方文档来实现接口的调用,但是文档编写者和开发人员之间有一个信息不对称,当开发人员错误使用API时会导致多种漏洞,如内存泄漏等。
因此想法是利用NLP对官方文档进行分析,从而实现辅助漏洞检测的研究,包括:检查文档声明与实现的不一致性、文档中的逻辑缺陷等。
现有的研究主要利用了NLP技术中的命名实体识别、词性标注、依存句法解析、语法分析、语义消歧等对自然语言文档进行分析,从文档中提取规则和约束等,从而辅助代码中漏洞的发现。
该研究的局限性:
问题1. 提取文档中API使用限制的方法存在有一定局限性,如:Advance和Atomic难以处理描述模糊的语句,会产生一定的误报或漏报(即提取质量收到文档编写质量的限制)。
问题2. 能够研究的漏洞类型相对单一,例如:Atomic仅能研究DoS相关的漏洞类型。
作者提出的研究方向
- 探索如何解决NLP技术难以处理文本信息中描述模糊的语句问题
- 探索如何解决利用官方文档进行漏洞检测时漏洞类型单一的问题
总体来说这个方向是对漏洞检测的一个辅助手段,自动化检测文档中的缺陷和错误,能够为程序分析(如模糊测试)提供指导,从而更有效的检测漏洞。
一些已有方法的研究对比:
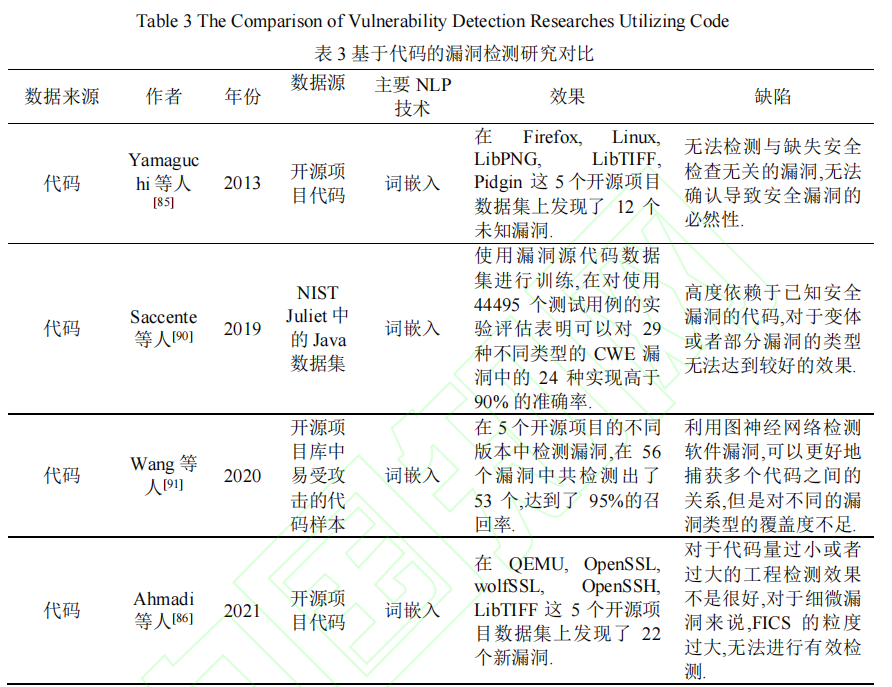
基于代码的漏洞检测研究
- 由于源代码数量巨大,人很难仅从源代码中归纳并提取出编程规则的限定条件。因此,Engler等人提出了一种自动化提取某段代码中的约束限定条件的方法.在不需要额外信息的情况下,仅从源代码中提取函数的使用限定.提出“以大多数代码的表现形式为基准,少数与这些形式不同的代码为潜在错误”的思想,该思想后续也被广泛应用到研究中。
- 基于Engler 的工作,Wang 等人提出“当一种模式没有以很高的频率出现时就不会形成规则,将会对漏洞产生漏报”。在代码集上出现频率较低的标记序列是不正常的,这些标记序列可能会导致错误和漏洞。基于此想法,该团队研究出了一个新的工具,利用n-gram语言模型对程序的调用序列进行统计,并进行漏洞检测。
也有一些其他的研究试图直接在代码集中检测漏洞,但是由于无法实现对大规模代码的自动化漏洞检测,反而降低了效率。
经研究人员发现,许多漏洞是由于对输入检查不充分导致,因此缺少检查为漏洞检测提供了总要信息。
Yamaguchi等人提出CHUCKY,通过对代码进行污点分析并识别出安全关键性对象的异常或缺失条件,加速人工审核的过程。其思想为“大多数代码的表现形式是正确的”,认为缺少检查或者错误检查是罕见事件,并且对软件项目中的安全关键性对象施加的大多数条件都是正确的。的.因此,CHUCKY 通过对给定函数源码进行语法分析,在代码集上对具有相似的函数进行检测确定与给定函数相关的安全检查,对给定函数和与它相似的函数进行分析,最终计算出一个模型对函数进行正态分析,并实现对缺失安全检查的检测
当前有些研究尝试了从已知漏洞学习规则来检测未知漏洞,并已经形成大范围运用,但是这个方法存在一定缺陷:1)模型训练的过程需要输入大量已知漏洞的数据,才能在一定程度上降低误报率;2)大多数模型只能针对特定类型漏洞的检测。
FICS:以大多数代码的形式为基准,以偏离这些代码的表现形式作为检测漏洞的基础。其从当前代码集上提取代码片段(construct),利用“2步”聚类方法来检测代码中功能相似的代码片段,最后检测这些片段中与大多数代码形式不一致的部分实现对不一致漏洞的检测。FICS利用了程度的数据依赖图(DDG)来提取代码片段,该图通过保留程序依赖图(PDG)中的数据依赖边,去掉控制依赖边生成。从根节点出发,遍历数据依赖图中的所有子节点,当遍历所有子节点或达到Construct最大深度时,形成了最终的Construct。利用根节点和最大深度能够唯一确定Construct。Ahmadi发现如果将边排除,能够最大程度不影响计算Construct的相似性。因此他们借鉴了口袋模型的思想,提出了bag of nodes,只考虑节点,将每一个Construct嵌入到一个节点向量中,通过计算向量的余弦相似性来检测Construct。但是这个在代码量过小和过大的开源软件上效果都不太好,原因是这个Construct的粒度仍然比一些漏洞要大。
Geniu:该方式通过将控制流程图转换到高阶数字特征向量中,能够解决基于传统控制流图的检测工具无法在大规模的IoT设备上实现漏洞检测的问题。
另一个工作是代码中的变量和函数名在一定程度上提供某些种类漏洞提供语义信息,但是当前研究往往忽略了这个信息,导致可能会产生漏报。之后Pradel等人提出了一个新的技术“DeepBugs”,能从代码中将语义相近的标识符识别出来。
有的时候相似性检测也可以用来进行漏洞检测、抄袭检测,现有研究使用相似图匹配的方法进行相似性检测,但是在一定程度上非常耗时且易出错,普适性较差。后来Xu等人提出了一个工具Gemini,对每个二进制函数生成其控制流程图,对他们进行embedding,通过计算vector的距离来检测相似性。(这种方法也同样是借助了word embedding的想法)。 在这之后,Saccente等人提出了Project Achilles,同样利用word embedding方法对source code进行表征,然后利用LSTM来检测漏洞(有点好奇,这个是怎么做到的?),对29中CWE中的24中检测率能高于90%,但是对其他的检测力不足。
Wang等人提出了FUNDED框架,利用word embedding对代码的语法信息进行学习,利用GNN捕获程序的控制、数据和调用依赖。
作者提出的研究方向
- 探索如何解决代码规模对漏洞检测效果影响的问题
- 探索如何在单一数据源上监测多种类型漏洞的问题
横向对比图
基于代码注释的漏洞检测研究
起因:开发人员通常会将代码的功能以及限制写到注释当中,例如:微软开发的源代码注释语言(source-code annotation language, SAL)可以用来注释参数和返回值。该语言不仅可以帮助用户理解代码含义,还可以辅助静态分析工具以低误报率和低漏报率自动化且准确地分析代码。
前提:这个注释也是一种规范化的语言,主要想法是根据注释和代码的不一致性进行辅助检测。当前研究中大多以word embedding和句法分析的方法进行关键信息提取,对代码和注释进行相应匹配。
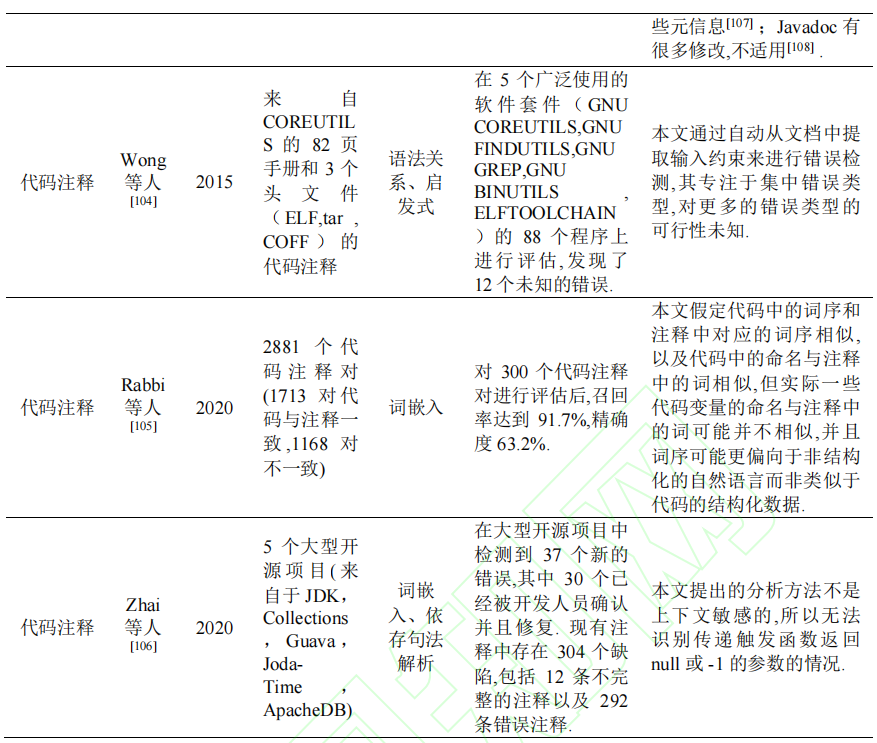
Tan等人利用NLP对代码注释进行自动化分析,并将其语义和代码进行比较,检测他们之间的不一致性,进而检测潜在安全漏洞以及恶意代码注释。其工具为iComment,准确率达到90.8% ~ 100%。但是这个工具在处理和中断相关”interrupt-related”的注释时准确率会降低。之后提出了新的工具aComment,对中断相关的前置和后置条件进行提取,再利用这些信息检测程序中与中断相关的并发缺陷 。2012年这个团队又提出了tComment工具,关注点转移到了C/C++编写的系统代码上和锁协议、函数调用以及中断错误上。同时由于Javadoc文档的规范性,无需使用NLP技术对注释进行处理。
Wong等人提出DASE进行改进。DASE利用的是NLP中的语法关系来分析文档(包括手册和注释)自动提取输入约束。但是只适用于几种错误类型,暂时不知对其他的错误类型是否可行。
Rabbi等人利用siamese recurrent network解决代码和注释序列不一致问题。其想法是对代码和注释都进行word embedding,然后各自使用一个LSTM进行学习,利用相似度来检测不一致性。实验效果准确率63.2%,召回率91.7%。
当前研究存在的问题
- 检测领域单一,通用性不高。
- 对跨语言平台无法检测,如多语言开发。目前仅针对C/C++的代码注释进行分析。
横向对比

基于漏洞相关信息辅助漏洞检测研究
背景:有研究人员发现CVE中对漏洞的描述也有助于漏洞检测。漏洞报告中提供了漏洞代码本身或者官方漏洞数据未提供的信息。
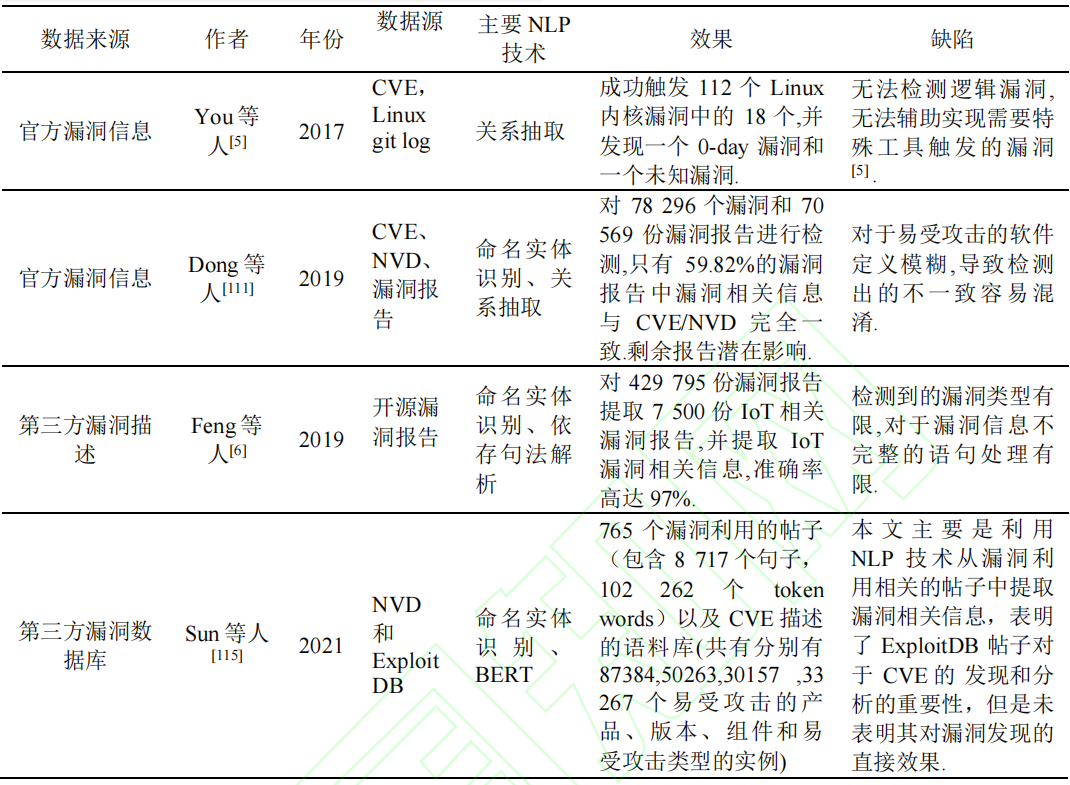
You等人提出了SemFuzz工具,改工具利用NLP技术对漏洞的描述和Linux git logs进行分析,提取和漏洞有关的信息,例如:受到漏洞影响的版本、有漏洞的函数、漏洞类型、系统调用等。之后SemFuzz能够利用这些信息生成针对性的测试用例。
另一个角度:看CVE和NVD之间描述的区别,如果有些地方不一致,会导致依据这些内容打补丁的程序存在有安全隐患。同样,这两个都是针对漏洞类型、版本等的基础描述,可以使用NLP的方式进行检测。
作者认为的研究方向
- 探索如何在单一数据源上实现多种漏洞检测问题
- 探索如果解决当前NLP技术难以处理长难句的问题(感觉是NLP那边的问题吧,或者可以试图将长难句给拆解?)
横向对比
利用NLP进行其他工作
漏洞复现
前提:漏洞报告内容要详细且准确。报告中应当清晰地描述观察到的行为、复现步骤以及预期行为。
Chaparro等人的工作是利用词性标记和启发式的方法来识别一个报告是否完整,是否具备复现步骤和预期行为。
Zhao等人提出ReCDriod,利用词性标注和依存句法分析来分析报告,采用22条语法规则从报告中提取复现错误相关的事件表示,从而进一步实现自动化漏洞复现。
漏洞修复
Nappa等人对漏洞的补丁进行研究,利用NLP从文本描述中找到易受攻击的范围,从而自动化比较文本中描述的范围和NVD XML转储中的易受攻击版本。
以上两个目前还没有太多成果,发展空间很大
存在问题
